David M. Lloyd
Software Engineer at Red Hat, Inc.
Circular Module Dependencies and the Real World
by
In a somewhat recent discussion on the jigsaw-dev mailing list, the issue of circular dependencies during compile time versus run time came up again (previously discussed way back in March 2012) without apparent resolution. At run time, systems like JBoss Modules can take advantage of the JDK’s lazy class loading behavior in order to lazily link modules, even circularly, as required to link module classes. Introducing support for circular runtime dependencies was relatively simple using a multi-phase resolution strategy. This is (uncoincidentally) very similar, in fact, to the mechanism (and reasoning behind the mechanism) of JDK class loaders themselves. However, things become uglier at compile time. The compiler must have a complete picture: any symbol referenced from any source file must be defined in either a class file on the class path or another source file, otherwise the compiler can’t tell if your Foo.Bar is a field on class Foo or a nested class called Bar inside of Foo or a top-level class Bar in a package named Foo. But what do you do when you have two modules that have requirements on one another? The current javax.tools API only has a notion of a single source and target, hence the March 2012 discussion. If you want to compile two interdependent modules today, you can either build them as one (which, if you’re using Maven like 90% of the world, results in one JAR unless you do some trickery) or you hack javax.tools with some scheme to map the class files to their proper output directories - in both cases building the two modules at the same time.
Lock ‘em down
It has been argued on jigsaw-dev that at compile time, your compile-time dependency graph should always be a directed acyclic graph. This means that the problem simply never comes up; there is no possible way you would ever have to compile more than one module at the same time. The argument is in several parts, the most interesting of which are: if the compile-time aspect of the module system is strict now, it is simpler (and thus better) and you can reap other rewards later, such as better static analysis tooling; and, to quote Tim Boudreau: “Fundamentally, if you are developing two things, and there is a circular dependency between them, you do not have *two* things - you have one thing which you enjoy pretending is two. If neither can exist without the other, their independence is in illusion.” The counter-argument given strikes me as, well, being more along the lines of “Strict Bad! Free Good! No Take Free!”. But within the generalized indignation there are hidden some useful insights.
Reality bytes
In the “real world” of modular application development (presently a very sparsely-populated world indeed), we (the WildFlyteam) have developed and/or integrated a fairly large number of modules (from diverse origins) into the static module repository that makes up the bulk of the WildFly application server distribution. This I think gives us a unique perspective into this problem: we develop in-house many independent frameworks, which, on occasion, are interdependent - and I’m not just talking about taking some single large project and arbitrarily dividing it into JARs to satisfy some code size ideal. I’m talking about truly distinct projects by truly distinct teams, with distinct goals and maybe even differing licenses. What happens is, two projects are developed independently. But it soon becomes clear that project A might see something useful in project B, and they may decide that this feature might be useful (maybe even on a purely optional basis). So they add B as an optional dependency at distribution and a required dependency at compile time.
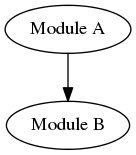
The problem occurs when project A notices something possibly useful in project B, and decides they want to leverage it. Only now, it becomes impossible: if you compile A you need B, but to get B you have to compile B which requires A.
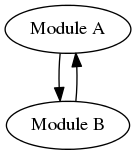
The ideological solution
Conventional wisdom in this case would suggest that if I have a module A which depends on module B as explained above, I should factor out the integration bits such that A’s integration with B would go in some separate AB library which has a compile-time dependency on both A and B to provide these optional features. The A module would introduce an SPI which would allow me to integrate my AB module without requiring a dependency from A to AB.
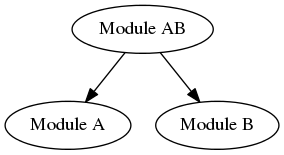
Great! Now when B adds its dependency on to A, we can do the same thing:
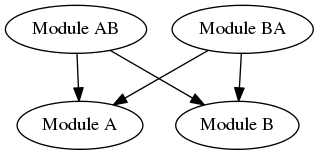
We’ve solved the problem elegantly, if somewhat expensively (after all, we now have four modules instead of two, and we’ve written new SPIs to both module A and module B to accommodate this arrangement), restoring our graph to proper acyclicity.
Reality bytes 2
However, it’s common to go beyond this simple two-module arrangement. Modern frameworks are complex and may integrate with a multiplicity of other frameworks. It is not hard to imagine the scenario getting out of hand:
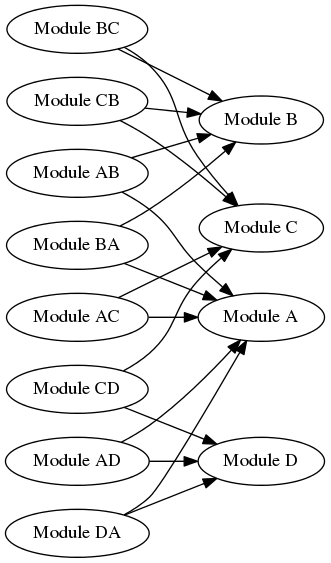
This is either heaven or hell, depending on where you fall on the academic-versus-pragmatic spectrum. In this example we have developed as many as 16 different SPIs and 8 extra modules; it is clearly possible to encounter a geometric increase in the amount of development effort to completely integrate a given number of modules (though in the real world you will rarely if ever encounter a complete mesh of interdependencies in projects which are truly independent).
Practical approaches
Natural evolution
Most libraries and frameworks don’t just appear one day, wholly formed. They tend to evolve from earlier, simpler versions, with new features being added gradually over time. In some cases, this may give rise to a natural solution. If module A starts using module B, best practices will dictate that A choose a known, stable version of module B to build against. If, later on, module B starts using module A, it merely has to consume a version of A that predates the dependency on B - or even simply predates the exact version of B currently being built. This in effect gives you a graph like this:
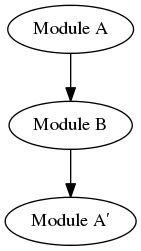
Generally this works when you have an A on-hand, and you want to use it to make a B - and then later you have that B on-hand and you want to use it to make an A. But imagine you are, say, a Fedora maintainer who wants to build everything from source. Do you then go and build the entire version history?
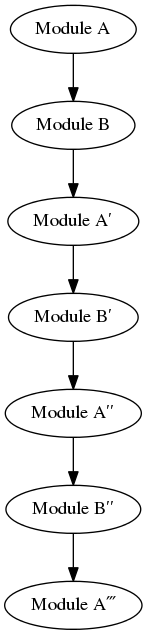
As you can see, this has potential to get quite out of hand, even if it is a fairly “pure” solution. This problem can however be mitigated by being diligent about maintaining (and guaranteeing) your pre-built history, in which case you’d only ever have to build a long chain one time, if at all. After that you would have permanent history that you could leverage at any time. I will admit that this solution is what I find to be most appealing; it is quite similar to the status quo in terms of what we have in Maven repositories - a more-or-less permanent record of pre-built binary files - granted that the exact provenance of such artifacts cannot always be well-established, especially in Maven Central where it cannot be known for certain whether the binary artifacts were built from the corresponding source.
Practical and dirty
There is, however, another perhaps more “traditional” (if a bit uglier) solution to this problem. When building module A, I can work around the problem altogether by simply acquiring the source for module B and building it at the same time as A, but then discard the resultant classes. When building B, I simply reverse the process. In this way, the compiler is satisfied (provided that I made sure to put B’s compile dependencies on the class path as well as A’s), and I can build A even with a version of B that depends on the exact version of A being built!
It’s up to the build tooling
I’ve given a few possible methods to support circularity (all of which, by the way, will work with today’s JDKs, and in fact are almost certainly in use now), but there are very likely to be other viable approaches as well. I do believe however that one way or another, it is up to the build tooling to make this work in a usable way.
tags: